Research
* indicates equal contribution.
+ indicates corresponding author.
Representative papers are highlighted.
|
|
|
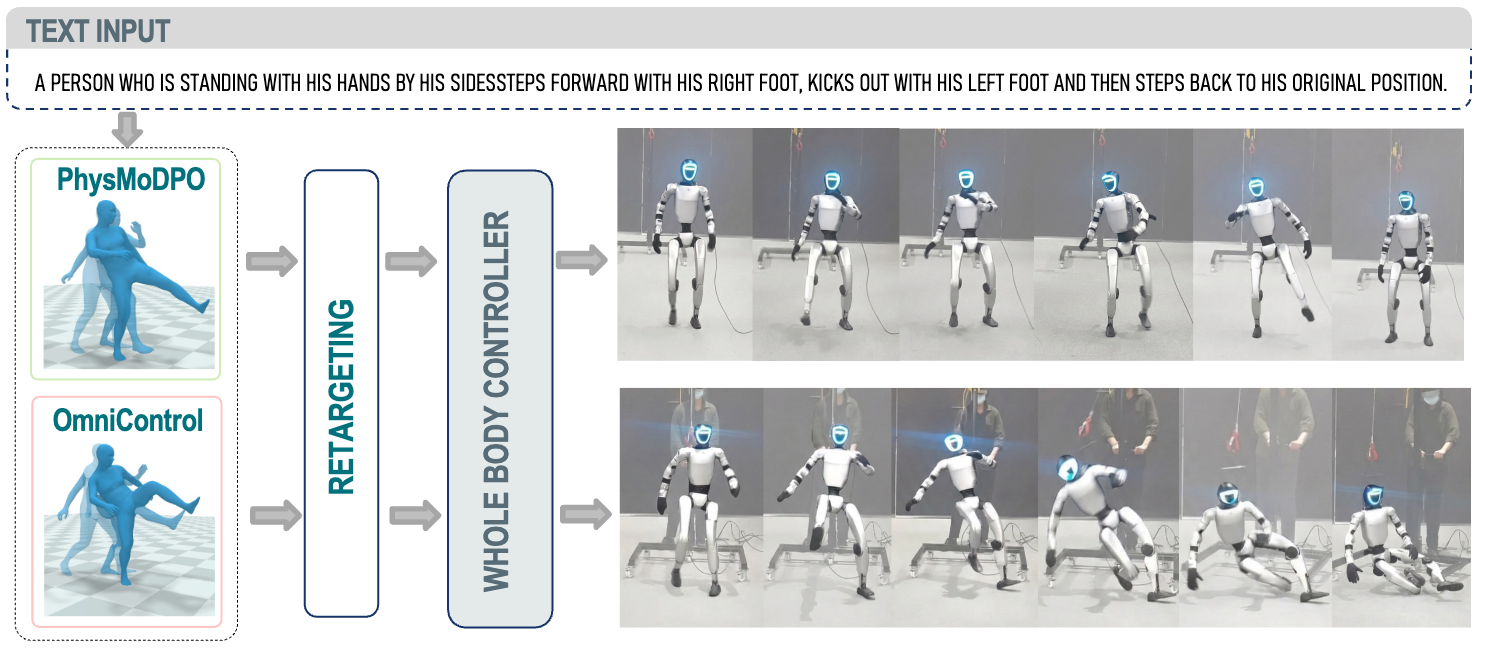
PhysMoDPO: Physically-Plausible Humanoid Motion with Preference Optimization
Yangsong Zhang,
Anujith Muraleedharan,
Rikhat Akizhanov,
Abdul Ahad Butt,
Gül Varol,
Pascal Fua,
Fabio Pizzati,
Ivan Laptev+
arXiv, 2026
[Project page]
[PDF]
[Code (GitHub)]
Star
|
|
|
InterPose: Learning to Generate Human-Object Interactions from Large-Scale Web Videos
Yangsong Zhang,
Abdul Ahad Butt,
Gül Varol,
Ivan Laptev+
3DV, 2026
[Project page]
[PDF]
[Dataset]
[Code (GitHub)]
Star
|
|
|
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
Jianrong Zhang*,
Yangsong Zhang*,
Xiaodong Cun,
Shaoli Huang,
Yong Zhang,
Hongwei Zhao,
Hongtao Lu,
Xi Shen+
CVPR, 2023
[Project page]
[PDF]
[Code (GitHub)]
[Online demo (Colab)]
Star
|
|
|
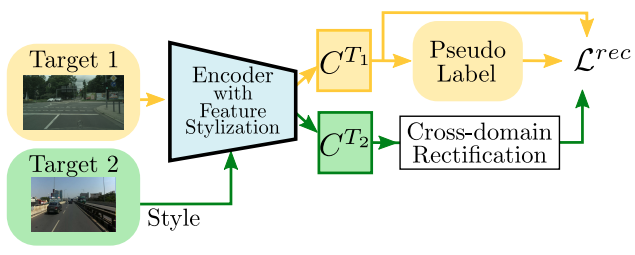
Cooperative Self-Training for Multi-Target Adaptive Semantic Segmentation
Yangsong Zhang,
Subhankar Roy,
Hongtao Lu,
Elisa Ricci,
Stéphane Lathuilière+
WACV, 2023
[PDF]
[Code (GitHub)]
Star
|
|
|
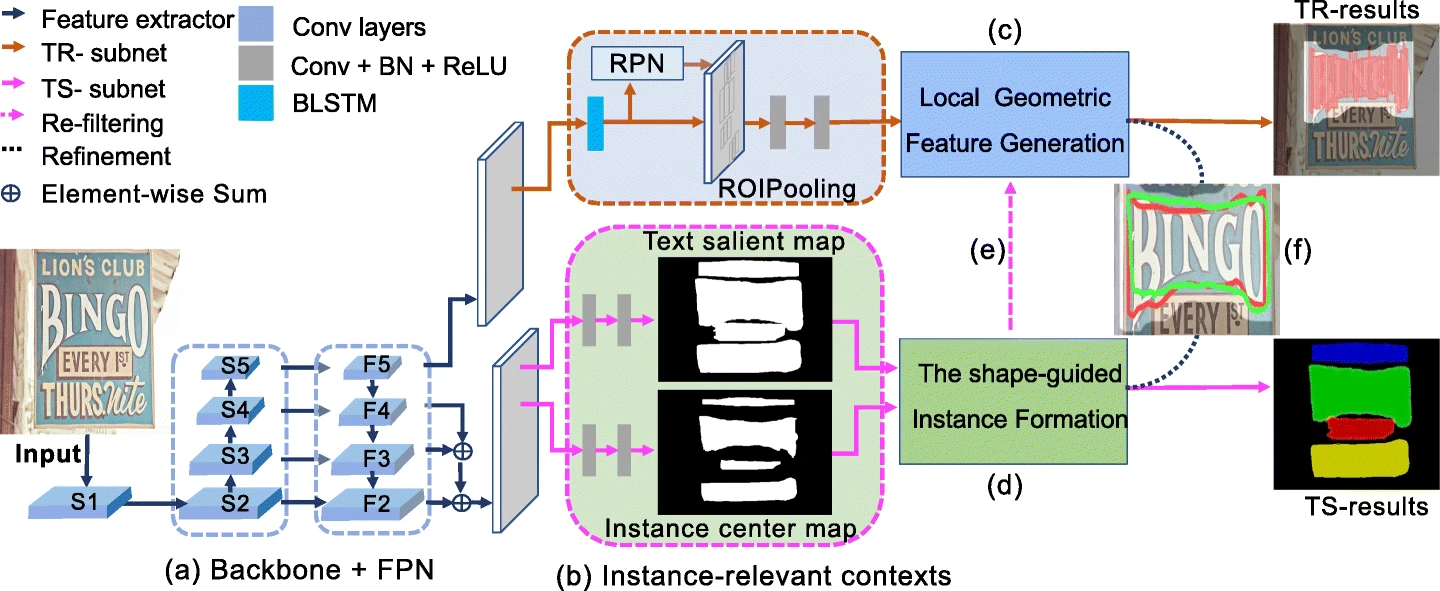
Arbitrary shape scene text detector with accurate text instance generation based on instance-relevant contexts
Haiyan Li
Yangsong Zhang,
Bayram Bayramli,
Hongtao Lu+,
Multimedia Tools and Applications, 2023
[PDF]
|
Misc.
Academic Services
IJCV, 3DV, CVPR.
Coding
All of my released code is maintained on my GitHub account .
|
 unique visitors since Sep 2023
unique visitors since Sep 2023
|
This website takes the template from here.
|
|
|

 GitHub
GitHub Google Scholar
Google Scholar